An illustration of next word prediction with state-of-the-art network architectures like BERT, GPT, and XLNet
Hands-on demo of text generation using Pytorch
Hi Friends!
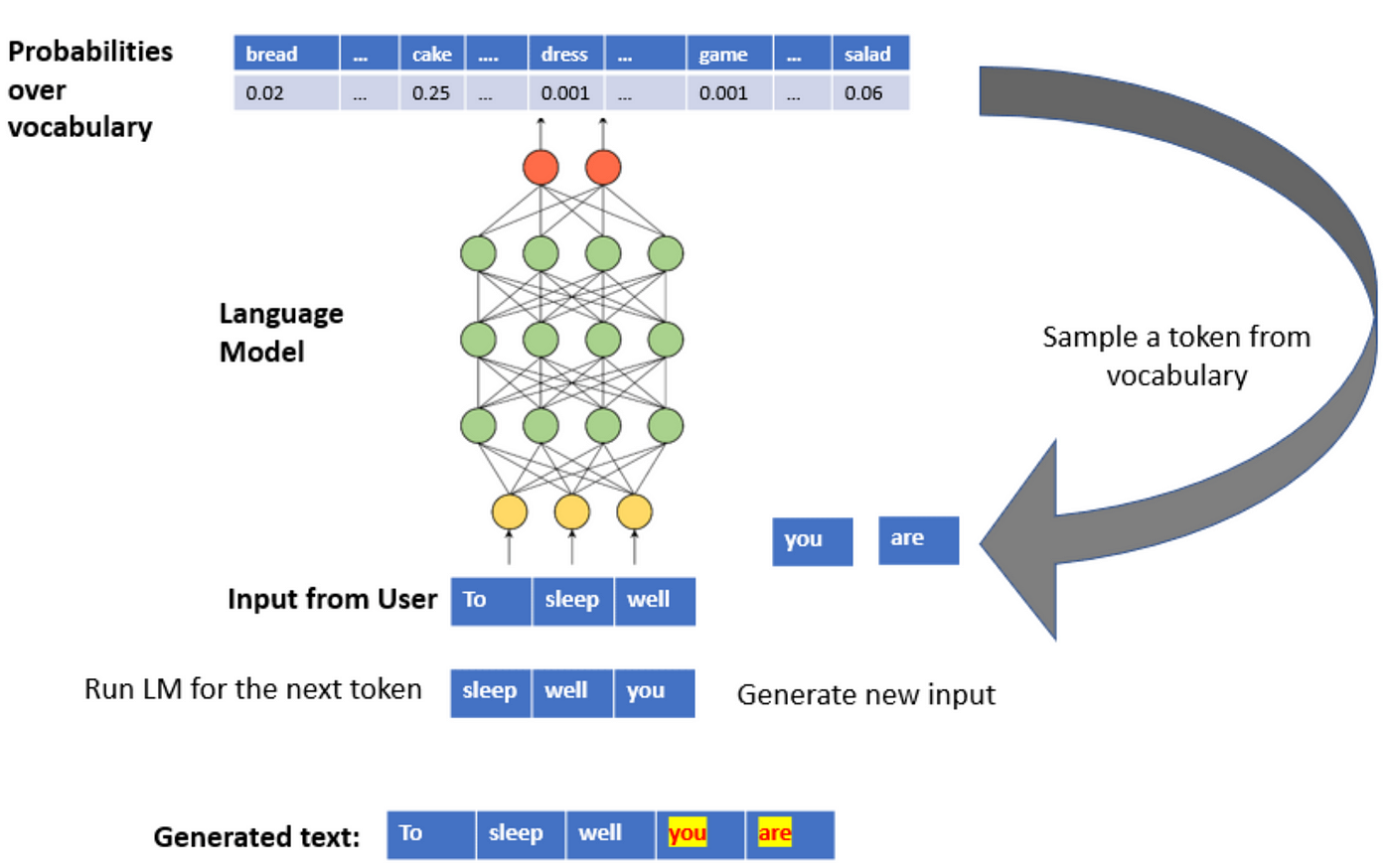
Welcome to the world of Natural Language Processing (NLP). One of the key aspects of us humans is the ability to communicate. Language plays a major role in the way we communicate with each other. How is all this language processing done in our brain? How do we use words to communicate, and how such communication is processed & interpreted? These are all the immediate fundamental questions that could arise for us. I will not get too much into the neurolinguistics & neuroscience aspects but would encourage all the interested readers to go through the reference materials listed in the reference section. Sticking back to our focus, “NLP” in layman's terms is all about how machines can process, analyze, and interpret large amounts of natural human language data, i.e., mainly the interactions between machines and human language. The current state-of-the-art networks give machines the ability to learn and mimic human-like tasks. Isn’t this all fun? We will discuss some important network architectures with a demo to see, how for the given input text we can predict the next set of words with these language models. We are all very well familiar with the GMAIL-SMART COMPOSE feature by now & been using it regularly as seen in the figure below. This was rolled out by Google in 2018.

In this tutorial, we shall see how we can use pre-trained NLP models for predicting the next set of words for the given input sentence with different state-of-the-art deep neural network models like
- BERT — Bidirectional Encoder Representations from Transformers
- GPT — Generative Pre-trained Transformer
- XLNET — Transformer-XL model pre-trained using an autoregressive method
Now, if you notice, all the above three mentioned network architectures are based on the transformer family. So, what exactly is a transformer? The transformer is a component used in many neural network designs for processing sequential data, such as text data, genome sequences, sound signals or time series data, etc. Transformer models have become the frontrunners for NLP tasks. So, quickly let’s dwell through the basics of the Transformer model. There are tons of materials, posts, and references out there on this, so I won’t go into many granular details. Let’s just understand things to get an basic overview.
USP of Transformer Network
Transformers are a very interesting family of deep learning architectures, introduced in 2017 (Google Brain). The fundamental operation of any transformer architecture is the self-attention operation. What exactly is self-attention then? The attention mechanism is what enables this network architecture to go beyond the attention limit of a typical RNN or LSTM model. Traditional Sequence-to-Sequence models discard all of the intermediate states, and use only the final state/context vector when initializing the decoder network to generate predictions about an input sequence. Discarding everything, but the final context vector works okayish when the input sequences are fairly small. But, when the length of an input sequence increases, the model’s performance will degrade while using this approach. This is because it becomes quite difficult to summarize a long input sequence as a single vector. The solution is to increase the “attention” of the model, and utilize the intermediate encoder states to construct context vectors for the decoder. So, simply the attention mechanism defines how important other input tokens are to the model when encodings are created for any given token.
Why is Transformer architecture more relevant nowadays?
From 2019, Google Search has begun to use Google’s transformer neural network BERT for search queries in over 70 languages. Prior to this change, a lot of information retrieval was keyword based, meaning Google checked its crawled sites without strong contextual clues. Take the example word ‘bank’, which can have many meanings depending on the context. The introduction of transformer neural networks to Google Search means that queries where words such as ‘from’ or ‘to’ affect the meaning are better understood by Google. Users can search in more natural English rather than adapting their search query to what they think Google will understand. An example from Google’s blog is the query “2019 brazil traveler to usa needs a visa.” The position of the word ‘to’ is very important for the correct interpretation of the query. The previous implementation of Google Search was not able to pick up this nuance and returned results about USA citizens traveling to Brazil, whereas the transformer model returns much more relevant pages. A further advantage of the transformer architecture is that learning in one language can be transferred to other languages via transfer learning. Google was able to take the trained English model and adapt it easily for the other language’s Google Search.
Also, if interested for any computer vision problem, then I would encourage to do check how a vision transformer model is used for a classification task here
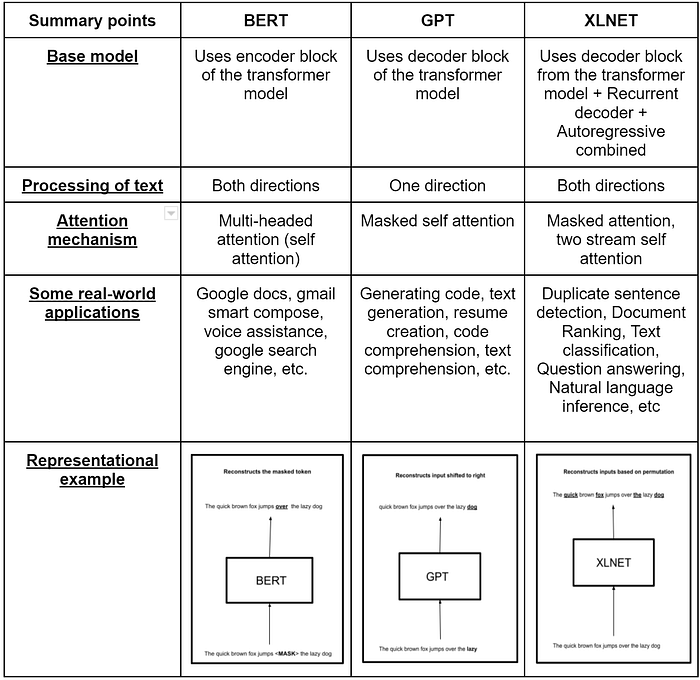
Overview of SOTA: BERT, GPT, XLNET
BERT is a transformer-based language model that learns the underlying representation from unlabeled text by jointly processing on both left & right context for learning. It has been pre-trained on Wikipedia and BooksCorpus.
For more in-depth detailed information go through these references — link, link
GPT is a transformer-based auto-regressive language model, which is pre-trained in a generative, and unsupervised manner. It is trained on tons of unlabeled text (e.g. wikipedia, books, movie scripts). The model will learn to estimate the probability of any given word sequence, even the one’s it has never seen before.
For more in-depth detailed information go through these references — link, link
XLNET is a generalized auto-regressive language model which outputs the joint probability of a sequence of tokens based on the transformer-based architecture with recurrence, where it captures bi-directional context using permutation language modeling. It integrates ideas from Transformer-XL, the state-of-the-art autoregressive model into pretraining.
For more in-depth detailed information go through these references — link, link, link
A quick summary is provided below:-
Example Demonstration
Now that we have some very basic idea of these neural network architectures, let’s see a simple demo of using these pre-trained NLP models for predicting the next set of words. Here, I will use the pytorch framework for this task. But, alternative one can use other deep learning frameworks too like tensorflow, etc. So, let’s get started. For this tutorial, we will be using the following main package “torch”, “transformers”. After installing the libraries, we will import all the necessary libraries, declare the variables for setting model configuration, create a function for taking arguments from user, function to load the corresponding model & it’s respective tokenizer, functions for encoding and decoding for the corresponding models, function to get all the predictions from the selected model, function to predict set of words after the end of the input text, and finally running the program
Step 1) Import libraries
Step 2) Declare the variables
Step 3) Create a function for initial model settings as input from the user
Step 4) Load corresponding model and tokenizer
Step 5) Create functions to encode & decode input text for the respective models
Step 6) Wrapper function for encoder and decoder
Step 7) Main execution of our program
Bert Model Output:-

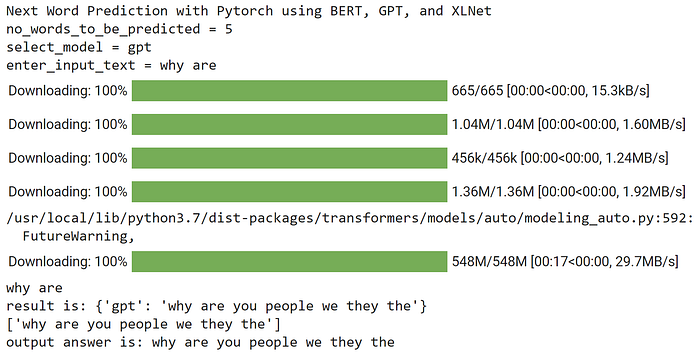
GPT Model Output:-
XLNet Model Output:-

Further TODO’S
- Develop a demo gmail-style web application with live inferences from these NLP models.
- Cross-validate this “Are Pretrained Convolutions Better than Pretrained Transformers?” as referred here
- Use the pre-trained model & fine-tune on your custom dataset (This I leave it to the readers for exploring)
- Try longer sequence of messages and uncommon sentences with out-of-vocabulary words (This I leave it to the readers for exploring)
- Check as to did padding text really help XLNet to perform better, if it did so, as compared to without any padding (This I leave it to the readers for exploring)
Conclusion
The pretrained language models have largely dominated the neural history of Natural Language Processing, especially the transformer-based pretrained models. So, what’s the next big thing along this direction? We can still touch upon several facets like “Machine reasoning for Down-stream NLP Tasks”, “Improvising Visual QAS”, and many more.
Here is the complete code for this post.
Contact
You can reach me at ajay.arunachalam08@gmail.com
Let’s connect on LinkedIn, Keep Learning, Cheers :)
References
https://en.wikipedia.org/wiki/Language_processing_in_the_brain
https://searchenterpriseai.techtarget.com/definition/natural-language-processing-NLP
https://en.wikipedia.org/wiki/Natural_language_processing
https://machinelearningmastery.com/natural-language-processing/
https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
https://en.wikipedia.org/wiki/BERT_(language_model)
https://en.wikipedia.org/wiki/GPT-3
https://arxiv.org/abs/1906.08237
https://huggingface.co/transformers/model_doc/xlnet.html
https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
https://en.wikipedia.org/wiki/PyTorch
https://huggingface.co/transformers/model_doc/xlnet.html
https://towardsdatascience.com/xlnet-explained-in-simple-terms-255b9fb2c97c
https://www.borealisai.com/en/blog/understanding-xlnet/
https://github.com/rusiaaman/XLNet-gen
https://towardsai.net/p/latest/gpt-3-explained-to-a-5-year-old
https://towardsdatascience.com/bert-for-dummies-step-by-step-tutorial-fb90890ffe03
https://towardsdatascience.com/gpt-3-explained-in-under-2-minutes-9c977ccb172f
https://360digitmg.com/gpt-vs-bert
https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335
https://www.cs.princeton.edu/courses/archive/spring20/cos598C/lectures/lec5-pretraining2.pdf
https://towardsdatascience.com/xlnet-a-clever-language-modeling-solution-ab41e87798b0
https://researchdatapod.com/paper-reading-xlnet-explained/
